5 Basics of Consulting Success: Part 1
Of all the qualities necessary to be a successful statistical consultant, none is more important than communication, even if that communication is only with your future self.
Of all the qualities necessary to be a successful statistical consultant, none is more important than communication, even if that communication is only with your future self.
There are actually 5 strengths you need to be a successful statistical consultant; communication, testing, statistics (duh), programming and general knowledge outside of your field.
I’ll be speaking about being a statistical consultant at SAS Global Forum in D.C. in March/ April. While I will be talking a little bit about factor analysis, repeated measures ANOVA and logistic regression, that is the end of my talk. The first things a statistical consultant should know don’t have much to do with…
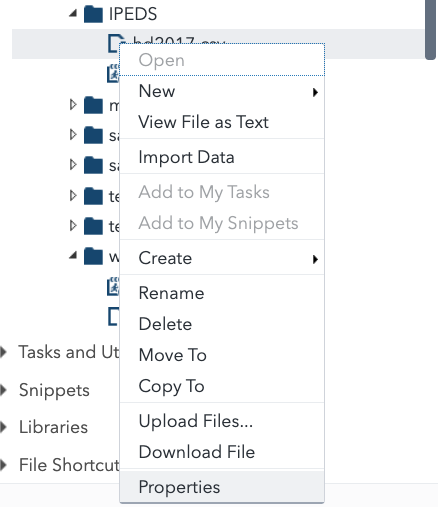
You can get data from PHPMyAdmin into SAS Studio with a dozen clicks, even if you know zero SQL.

If you’re the kind of statistical consultant that has a range of clients, the ability of SAS to easily read lots of data formats is a godsend for you.

First of all, I want to draw your attention to this retraction in the Journal of the American Medical Association and mad props to Drs. Aboumatar and Wise and John Hopkins for doing the right thing in publicly retracting it. For the TL; DR crowd Someone who is probably now unemployed miscoded the study groups…
The famous statistician, F.N. (for Florence Nightingale) David was a professor at UC Riverside, where I earned my doctorate. My advisor told this story about her: We were on this dissertation committee – I forget if it was for biology or what, back then, this was a small campus so if you were in statistics…

Never fear, I’m not going to post all 30 things in this post. This is a series. A LONG series. Get excited. I was invited to speak at SAS Global Forum next year and it occurred to me after thinking about it for 14.2 seconds that there are plenty of people at SAS and elsewhere…

A twitter storm erupted recently in response to one person’s thread about how to find a 10x engineer . Since I started programming FORTRAN with punched cards back in 1974, was an industrial engineer in the 1980s and now run a software company, I’ve worked with a few people, rightly or wrongly considered to fall…
One thing I like about our company a lot is none of our developers fit the stereotype of the 10x coder asshole. Don’t get me wrong, we have more than our share of people who are absolutely great at their jobs. What we don’t have is the arrogant attitude of: What do you mean you…