Quantifying Disease with SAS – who knew?
This month, I’m teaching biostatistics for National University, and so far I am really enjoying it. There is just a really minor problem, though. While I received a copy of the textbook, I did not receive a copy of the instructor’s manual with answers to the homework problems. Since I am going to grade 20 people based on whatever I get, I need to be 100% correct in everything and it is taking up my time to computer Cumulative Incidence for the population, cumulative incidence for people with hypertension, population attributable risk – and I am busy.
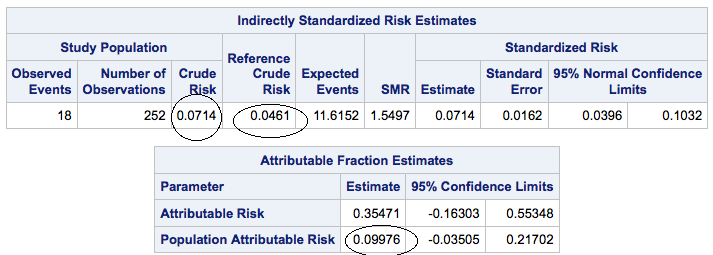
So, check this out, and all of you epidemiologists, I am sure this is old hat to you …. I had a table that gave me the number of people who were and were not hypertensive and whether or not they had a stroke in the five years they were followed. I wanted cumulative incidence for those with hypertension, those without and the population attributable risk.
And here we go …..
DATA stroke ;
INPUT Event_E Count_E Event_NE Count_NE;
DATALINES ;
18 252 46 998
;
proc stdrate data=stroke
refdata=stroke
method=indirect(af)
stat=risk
;
population event=Event_E total=Count_E;
reference event=Event_NE total=Count_NE;
run;
All I need to do is create a data set where I give the number of people who were exposed, (in this case, who had hypertension) who had the event, a stroke, in my example, and the total number of exposed people. Then, the number not exposed (that is, not hypertensive) who had the event, and the total number not exposed.
I just invoke the PROC STDRATE giving it the name of my dataset and specifying that I wanted risk as the statistics.
In my POPULATION statement, I specify that for the population of interest, people with hypertension, the number who had the event was found in the variable Event_E and the total number was in Count_E .
In my REFERENCE statement, I give the number who had the event and the total number for people who were not exposed to the risk factor.
That’s it.
One Comment