Errors in Repeated Measures ANOVA – let me count the ways
As I said in my last post, repeated measures ANOVA seems to be one of the procedures that confuses students the most. Let’s go through two ways to do an analysis correctly and the most common mistakes.
Our first example has people given an exam three times, a pretest, a posttest and a follow up and we want to see if the pretest differs from the other two time points.
proc glm data = example ;
model pre post follow = /nouni ;
repeated exams 3 contrast (1) /summary printm ;
Among other things, this will give you a table of Type III Sum of Squares that tells you that you have a significant difference across time. It will also give you contrasts between the 1st treatment and each of the other two.
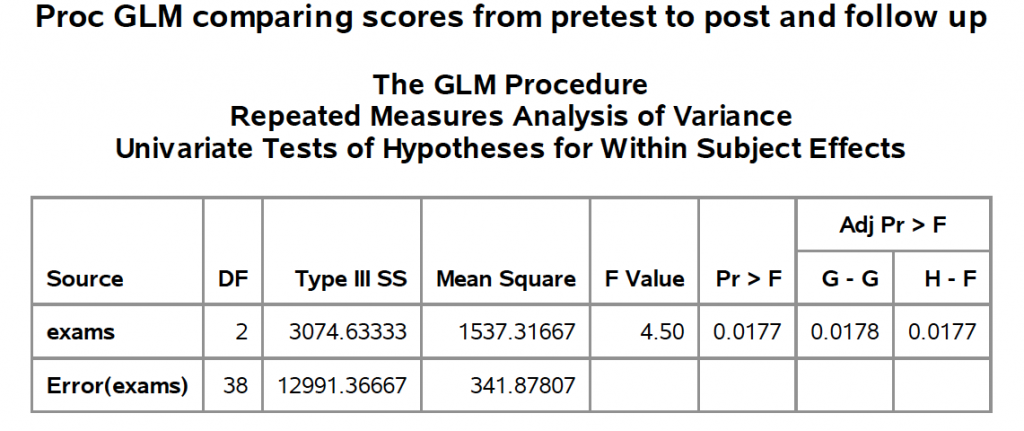
You can see all of the output produced here.
This is using PROC GLM and so it requires that you have multiple VARIABLES representing each of the multiple times you measured people. This is in contrast to PROC MIXED which requires multiple records for each subject. We’ll get into that another day.
One thing that throws people all of the time is they ask, “Where did you get the exams variable?” In fact, I could have used any valid SAS name. It could have been “Nancy” instead of “exams” and that would have worked just as well. It’s a label we use for the factor measured multiple times. So, as counterintuitive as it sounds, there is NO variable named “exams” in your data set.
Let’s try a different example. This time, I have a treatment variable. I have administered two different treatments to my subjects. I want to see if treatment has any effect on improvement.
proc glm data =example ;
class treatment ;
model pre post follow = treatment/ nouni ;
repeated exams 3 /summary ;
The fixed effect does *not* go in your REPEATED statement
In this case, I do need a CLASS statement to specify my fixed effect of treatment. A really common mistake that students make is to code the REPEATED statement like this:
repeated treatment 3 /summary ; *WRONG! ;
It seems logical, right? Why would you use a completely made up name instead of one of your variables? If you think about it for a minute, though, treatment wasn’t repeated. Each subject only received one type of treatment.
When you are asking whether one group improved more than the other(s) what you are asking is, “Is there an interaction effect?” You can see by the table of Type III Sums of Squares produced below that there was no interaction effect.
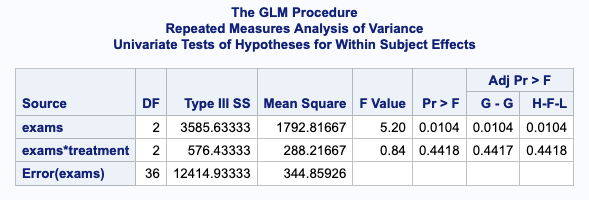
A significant effect for the repeated measure does not mean your treatment worked!
A common mistake is to look at the significance for the repeated measure and because a significant change was found between times 1 and 3 to say that the treatment had an effect. In fact, though, we can see by the non-significant interaction effect that there was not an impact of treatment because there was no difference in the change in exam scores across the levels of treatment.
There are a lot of other common mistakes but I need to go back to work so those will have to wait for another blog.

Another frequent issue is skipping the sphericity check and corrections (Greenhouse–Geisser or Huynh–Feldt) when using repeated measures ANOVA in PROC GLM. If sphericity is violated, the unadjusted F tests for the within-subject factor can be too liberal. That’s also a good reason to consider PROC MIXED, which models the covariance structure directly and avoids the sphericity assumption altogether.