Getting Started with SAS Enterprise Miner
I’m putting this here for my students this fall, but I’m sure there are two or three other people in the world who would like to know how to use Enterprise Miner. I’m assuming you read some of my other posts or received an email from your professor or in other ways got Enterprise Miner installed and running.
If not, you should read the documentation. Or, you are welcome to poke around on this blog and find out what I did. Just type “miner” into the search box.
To proceed:
- Start Enterprise Miner
- Create a new project
- Give it a name
- Create a new library so you have some data – File > New > Library
- Type in a name and your course library, something like “/courses/yourschool.edu1/a_123/b_456”
- Create a new diagram – File > New > Diagram
- Create a data source (this strikes me as counter-intuitive, since I have the data source in the library, but whatever. Here is how you do it
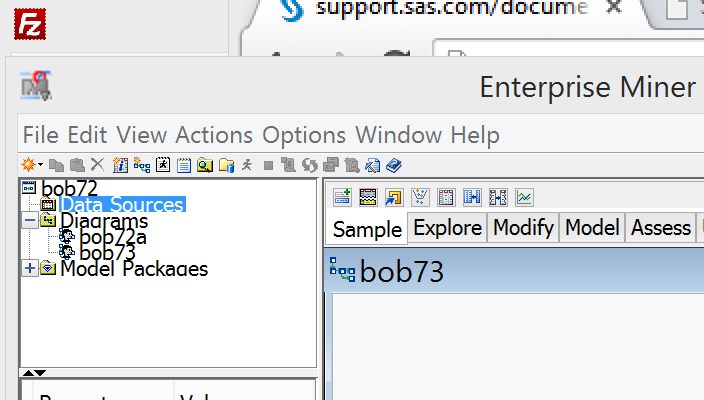
- * Right-Click on the data sources tab
- * it will come up with a drop down menu with 1 option, create data source
- * pick that
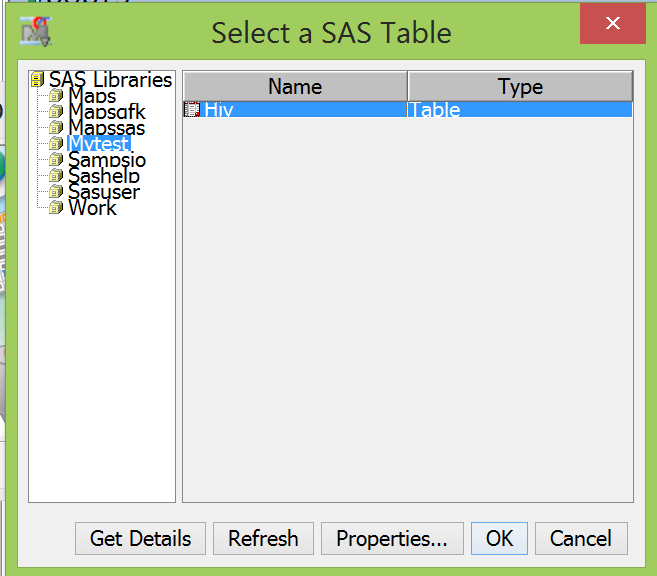
- * It will come up with this window.
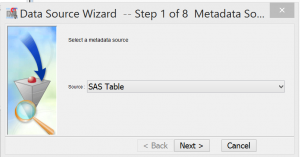
- Select SAS table, which is the exact same thing as a SAS data set
- * Click Next and it will bring up the list of libraries available including the one you just added in the last step
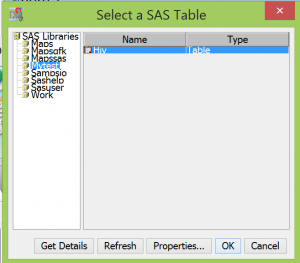
- * Double-click to select your library
- * Select your dataset and then
- Click OK
- The next few screens give you information on your data. In my course, the first assignment is for the students to use these to answer:
- How many variables in the data set
- How many observations
- .How many of these are nominal variables
- Select one of the variables that is NOT nominal. Click the explore tab.
- Write one paragraph describing these results. Include a screen shot of your results
- Click the COMPUTE SUMMARY STATISTICS tab
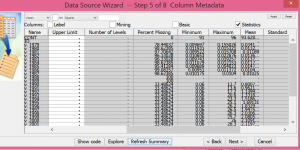
- Write a one paragraph summary of these results, only hitting the high(low)lights such as 98% of the data for variable v_1980 are missing.
Obviously this isn’t a feasible assignment if you have 6,000 variables, but I try to have courses that increase gradually in order of difficulty, starting with a relatively small data set and then going to gradually larger and more complex ones.
Hi Mars,
I have an issue with SAS enterprise miner. I am getting confused with the path used in creating the library. For eg. in your above article on comparing your 5th point and the following screenshot, I wonder how you chose Mytests folder when it’s not mentioned in your path
5. Type in a name and your course library, something like “/courses/yourschool.edu1/a_123/b_456”
Vs.
Screenshot = Select a SAS table
You’ve chosen MyTest folder
However, in the above path “/courses/yourschool.edu1/a_123/b_456” – there is no mention about the mytest folder