Pointy, Clicky Propensity Score Matching With SAS
Hopefully, you have read my Beginner’s Guide to Propensity Score matching or through some other means become aware of what the hell propensity score matching is. Okay, fine, how do you get those propensity scores?
Think about this carefully for a moment, if you are using quintiles, you are matching people by which group they fit into as far as probability of being in the treatment group. So, if your friend, Bob, has a predicted probability of 15% of being in the treatment group, his quintile would be 1, because he is in the lowest 20%, that is, the bottom fifth, or quintile. If your other friend, Luella, has a predicted probability of being in the treatment group of 57%, then she is in the third quintile.
Oh, if only there were a means of getting the predicted probability of being in a certain category – oh, wait, there is!
Let’s do binary logistic regression with SAS Studio
First, log into your SAS Studio account.
Second, you probably need to run a program with a LIBNAME statement to make your data available. I am going to skip that step because in this example I’m going to use one of the SASHELP data sets and create a data set in mu WORK library as so, so I don’t need a LIBNAME for that but, as you will see, I do need it later. Here is the program I ran.
data psm_ex ;
set sashelp.heart ;
if smoking = 0 then smoker = 0 ;
else if smoking > 0 then smoker = 1;
WHERE weight_status ne “Underweight” ;
libname mydata “/courses/blahblah/c_123/” ;
run;
My question is if I had people who had the same propensity to smoke, based on age, gender, etc. would smoking still be a factor in the outcome (in this case, death). To answer that, I need propensity scores.
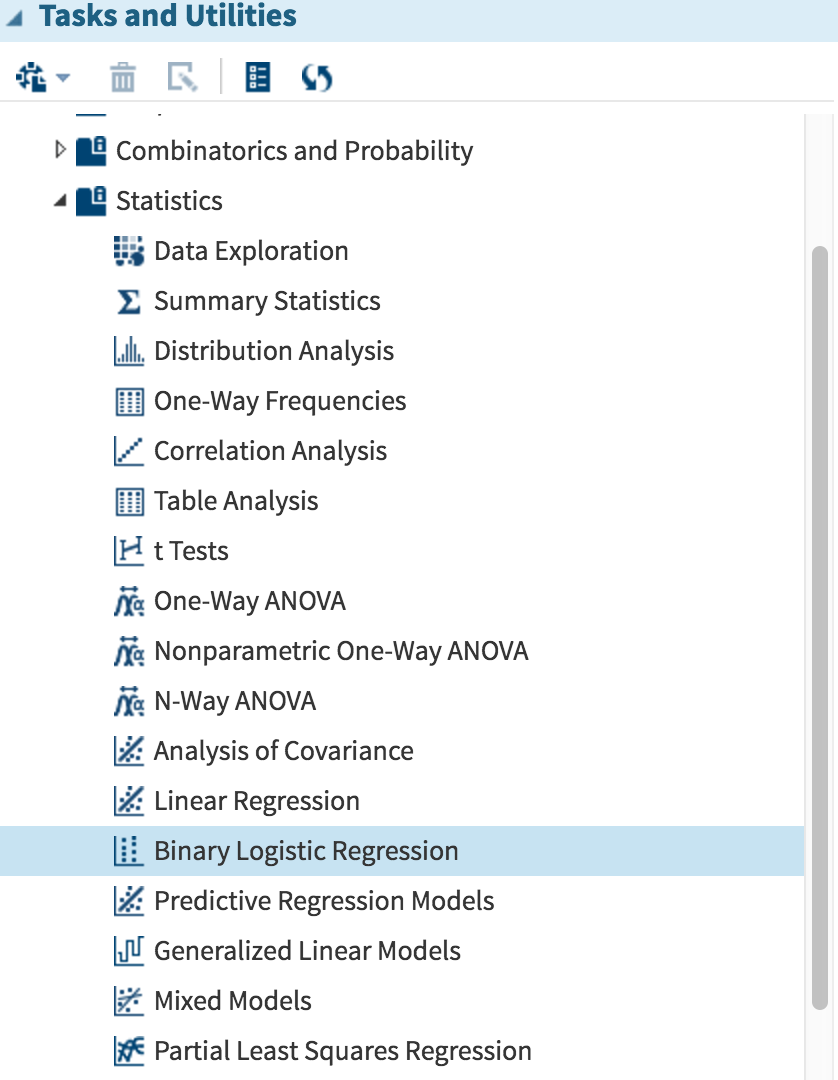
Third, in the window on the left, click on TASKS AND UTILITIES, then STATISTICS and select BINARY LOGISTIC REGRESSION, as shown below.
Next, choose the data set you want by clicking on the thing under the word DATA that looks like a table of data and selecting the library and data set in that library. Next, under RESPONSE, click the + sign and select the dependent variable for which you want to predict the probability. In this case, it’s whether the person is a smoker or not. Click the arrow next to EVENT OF INTEREST and pick which you want to predict, in this case, your choices are 0 or 1. I selected 1 because I want to predict if the person is a smoker.
Below that, select your classification variable,
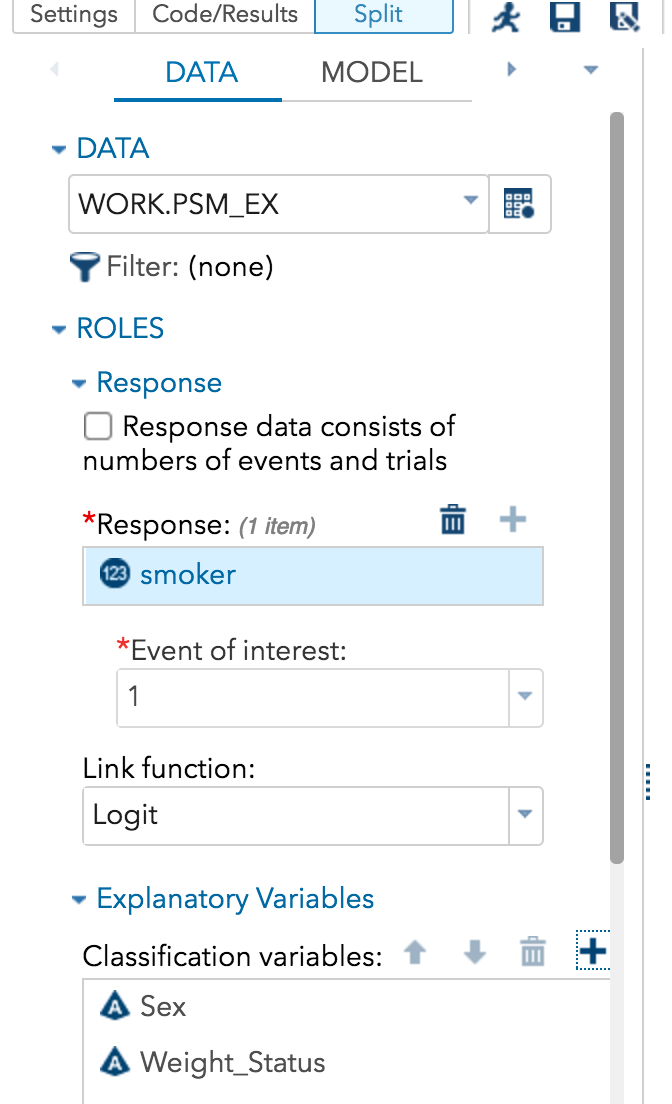
There is also a choice for continuous variables (not shown) on the same screen. I selected AGEATSTART.
I’m going to select the defaults for everything but OUTPUT. Click the arrow at the top of the screen next to MODEL and keep clicking until you see the OUTPUT tab. Click on the box next to CREATE OUTPUT DATASET. Browse for a directory where you want to save it. I had set that directory in my LIBNAME statement (remember the LIBNAME statement) so it would be available to save the data. Select that directory and give the data set a name.
Click the arrow next to PREDICTED VALUES and in the 3 boxes that appear below it, click the box next to predicted values.
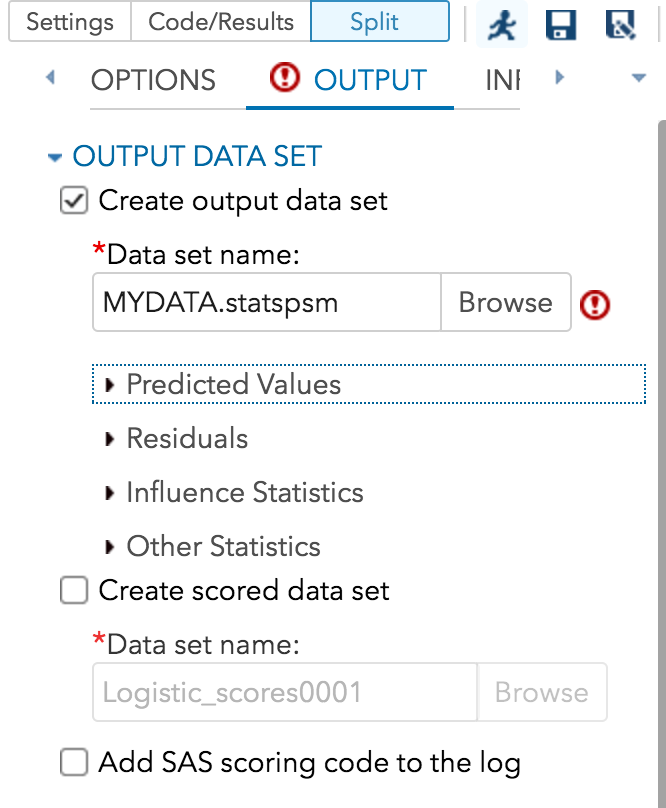
After this, you are ready to run your analysis. Click the image of the little running guy above. When your analysis runs you will have a data set with all of your original data plus your predicted scores.
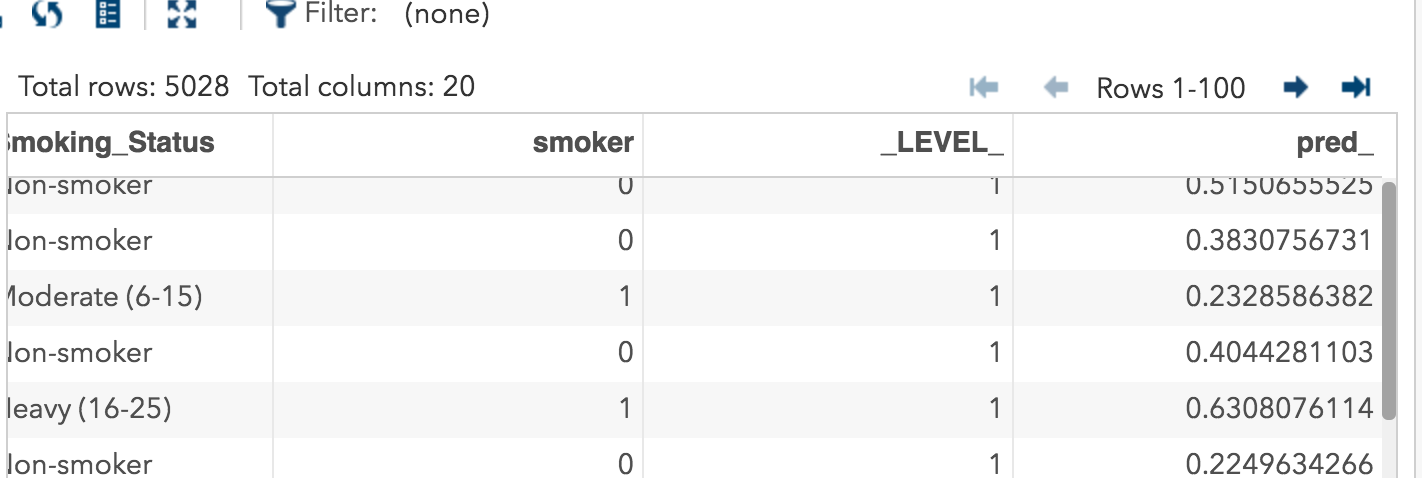
Now, we just need to compute quintiles.You could find the quintiles by doing doing this:
PROC FREQ DATA=MYDATA.STATSPSM ;
tables pred_ ;
and look for the 20th, 40th, etc. percentile
However, an easier way if you have thousands of records is
proc univariate data=mydata.statspsm ;
var pred_ ;
output pctlpre=P_ pctlpts= 20 to 80 by 20;
proc print data=data1 ;
Which will give you the percentiles.

For random advice from me and my lovely children, subscribe to our youtube channel 7GenGames TV
Hi, thanks for sharing this blog. This is very much helpful.
This is a very nice article with detailed and useful information. I’m really happy with the quality and presentation of the content. Thanks for sharing such a helpful post!