Starting with Perfect Data from SASHELP
More than once, I have said that I would never hire someone right out of graduate school. My reason is that graduate students come expecting perfect data sets to analyze, with no data entry errors, normal distributions of all variables, no missing data – and a liberal sprinkling of fairy dust to make it all perfect if it is not. The last new, young Ph.D. I hired complained bitterly about his inability to complete – nay, even start – the analysis I had asked him to do. He fumed,
“There are all kinds of problems with these data. There are 50 different ways people spelled Turtle Mountain Chippewa – TM Chippewa, TMT, TMBCI — did you know Ojibwe is another word for Chippewa? And it is sometimes spelled Ojibwa?”
I nodded. Yes, in fact, I did know all of that.
He continued,
“I can’t do anything with this study! SOMEBODY should do something about it! Someone needs to fix this!”
I told him unusually politely (for me),
“Why, you’re exactly right. That would be part of why we hired YOU.”
We were fresh out of fairy dust.

A few years ago, I acknowledged the fact that I was being a complete hypocrite because I taught graduate students and so it was partly my fault if they graduated with no experience with real data and unable to program their way out of a paper bag. (Why do we use that expression anyway? Who is so stupid to be stuck in a paper bag and if they were, how would programming help them?)
As I said yesterday, I cannot believe I did not mention using the SASHELP data before. Even though it sounds hypocritical (again) to admit that I start teaching with a perfect little data set from the SASHELP file shipped with SAS Enterprise Guide (including SAS On-Demand), if you were paying attention yesterday you would have learned a fine lesson that while it is great to teach your students two or three things you should try to teach them only one AT A TIME.
So … we start with SAS Enterprise Guide, open up the Server List by
Clicking on SERVERS, then
LOCAL, then
LIBRARIES, then
SASHELP, then
picking a data set. I picked the HEART data set.
What your students see now is the view below. Note the Server list in the bottom left pane.
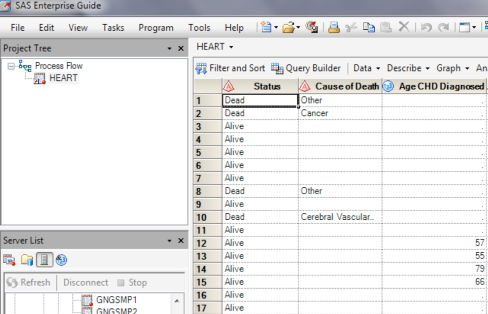
Now they have a nice little data set to play with.
There are no clerical errors where someone entered 999 instead of 99 for a patient age, missing data only occurs here and there for illustrative purposes. In short, the kind of data set you rarely encounter in real life unless you have put in a lot of work cleaning it. This makes these data sets perfect for use the first day of class when you are just introducing students to the software and you haven’t had time to get a data set of your own prepared for analysis.
The second part of that sentence is not to be overlooked. I taught full-time for many years and there was NEVER enough time to get prepared at the beginning of the semester. These days, I have the luxury of not taking any more work than I feel I could do excellently (as opposed to when I was younger, poorer and happy to be able to do passably decent work as long as I got a paycheck!) STILL … there are crunch times and it is great to have the option of a well-behaved data set ready to go.
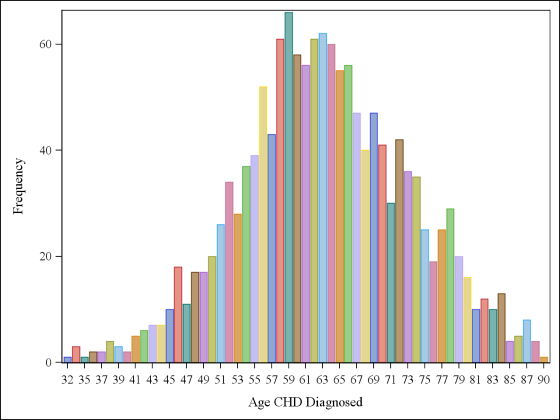
Because these data sets were prepared with teaching statistics in mind you should find almost everything you need – dichotomous variables, such as the dead vs alive in the first column above, normally distributed data you can graph for examples, like the age at which coronary heart disease was diagnosed, below.
Produced as part of the CHARACTERIZE DATA task, in case you were wondering,
( TASKS > DESCRIBE > CHARACTERIZE DATA )
So … you can start with some pointing and clicking on pristine data sets to teach your students about statistics, then move into doing the same with real data. I’ve written a lot about open source data here in the past, so let me just say that I am a fan.
Next, you can move to having your students review the code and ease into programming before they know it.
Also, I should mention that I have also taught with both SPSS and Stata and both of those also come with example data sets, although those Stata provides are a bit sparser than the other two.
The SASHELP data does have a lot of work behind it, although it’s not always perfect.
SAS Enterprise Guide comes with 130+ sample data sets (installed to the SASEnterpriseGuide\4.3\Sample\Data folder), which are described in AboutSampleData.txt (same folder). The “About” document describes each data set and includes possible analytical purposes. (Example: want to show ANCOVA? Look at the oysters data.)
And yet we teach theory instead of Perl.